개발
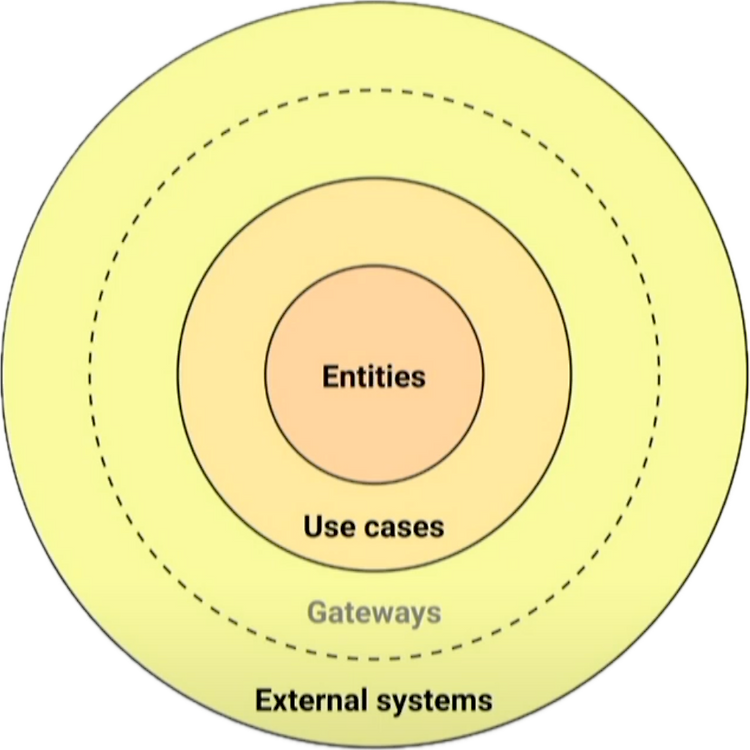
Clean Architecture in Python
https://youtu.be/C7MRkqP5NRI?si=NHG-qDp1cweFg7ue 이 글은 위의 영상을 정리하기 위해 필자의 개인적인 생각과 함께 작성된 글입니다.소프트웨어 아키텍처를 설계하고 이를 개발해 나갈 때 아래와 같은 고민을 하게 된다."어떻게 하면 변화에 강하고 확장 가능한 시스템을 만들 수 있을까?"이에 대한 답변으로 영상에서는 Clean Architecture를 위한 "The Golden Rule"을 제시한다. 이는 의존성 역전 원칙(Dependency Inversion Principle, DIP)을 바탕으로 시스템을 내부와 외부로 명확히 구분하여 유연성과 확장성을 극대화해야 한다는 원칙을 담고 있다고 생각한다.Clean Architecture우선, Clean Architecture를..

Github autoSetupRemote 설정
Github origin에 새로 판 브랜치를 push 하려고 하면, 아래와 같은 에러 메시지와 함께 원하는 대로 push가 안 되는 경우가 있다.fatal: The current branch test-branch has no upstream branch.To push the current branch and set the remote as upstream, use git push --set-upstream origin test-branchTo have this happen automatically for branches without a trackingupstream, see 'push.autoSetupRemote' in 'git help config'.자세하게 에러 메시지를 읽어보면, test-b..
Docker 환경에서의 Spring Boot Auto Reload (Hot Reload)
평소에 인터프리터 언어인 Python과 JavaScript를 사용한 서버 개발을 주로 해왔는데, 최근에 컴파일 언어인 Java를 사용한 서버 개발을 진행할 일이 있었다. 익히 알려져있듯, Spring 앱을 띄우려고 하면 Java는 컴파일 언어이기 때문에 jar 파일을 빌드하는 과정이 따로 필요하다. 이는 주로 인터프리터 언어를 사용해왔던 필자로서는 따로 컴파일 과정을 거쳐야만 서버에 수정 사항을 반영할 수 있다는 부분에서 크게 아쉬움이 느껴졌다. 위와 같은 언어의 근본적인 차이 때문에 아래와 같은 문제가 Docker 환경에서의 개발 진행 시에 아래와 같은 문제가 있었다.인터프리터 언어인 Python 기반의 FastAPI와 JavaScript 기반의 NestJS는 로컬에서의 소스 코드 변경을 Docker ..

Python은 Call by value일까, Call by reference일까?
최근 Python을 이용하여 알고리즘 문제를 자주 풀고 있으며 동시에 또 회사에서도 Python을 이용하여 백엔드 개발을 진행하고 있기에 Python에서는 어떤 방식으로 함수에서의 호출이 일어나는지 알아보고 싶어서 관련 내용을 정리하고자 한다.우선 이에 대한 정리 전에 간단하게 Call by reference, Call by value가 무엇인지 알아보고자 한다.1. Call by valueCall by value는 값에 의한 호출이다. 즉, 함수에 인자를 넘겨줄 때 인자에 "값"을 복사하여 넘겨준다는 것이다.함수의 실행 환경을 저장하는 스택 프레임에 인자의 값의 복사본을 담음으로써 함수 내에서 스택 프레임 내에 존재하는 값을 사용할 수 있도록 한다.그렇기 때문에 함수 내에서 만약 해당 인자를 변경하더라..

트랜잭션이란?
회사에서 최근 업무를 진행하면서 트랜잭션을 사용하는 일이 매우 많다. 현재 MongoDB를 이용하여 개발하고 있는 프로젝트에서 트랜잭션을 사용하고 있는 이유는 아래와 같다. 대용량의 데이터를 벌크로 처리해야하는 경우가 많은데, 이 때 하나의 데이터라도 유효하지 않거나 실행 중 실패가 발생한다면 모든 처리 내용을 롤백 시켜야 함 여러 사람들이 하나의 데이터에 동시에 접근하여 수정을 가하는 경우가 발생할 확률이 기획 상 매우 높음 여러 컬렉션에 위치한 여러 도큐먼트에 대한 삽입이나 수정이 하나의 서비스 로직에서 수행되는 경우가 많음 위와 같은 이유들로 트랜잭션을 진행하였고, 이들은 곧 트랜잭션으로 얻을 수 있는 가장 큰 장점들이다. 이렇게 개발 과정에서 어느 경우에 트랜잭션을 사용하는지는 알고 있지만, 이에..
단위 테스트(Unit Test)와 통합 테스트(Integration Test)
앞선 포스트에서는 테스트 코드란 무엇인지, 또 테스트 코드를 작성하는 이유는 무엇인지에 대해 간단하게 알아보았다. 테스트 코드는 왜 만들까? 테스트 코드는 왜 작성할까? 사실 백엔드 개발을 학습하면서 "테스트 코드가 중요하다. 실무에서 매우 중요하다." 이런 말을 정말 수도 없이 많이 들었었다. 하지만 이전까지 나의 프로젝트 경험 lildev.tistory.com 이번에는 테스트 코드의 다양한 종류와 각 종류 별로 소프트웨어의 어떤 부분에 집중하는지, 그리고 그중에서도 특히 단위 테스트와 통합 테스트에 대해 자세하게 알아보겠다. 테스트 코드의 종류 테스트 코드에는 단위 테스트, 통합 테스트, 부하 테스트 등 우리가 흔히 들어본 테스트 방식뿐만 아니라 인수 테스트, 회귀 테스트, E2E 테스트 등 정말 많..
테스트 코드는 왜 만들까?
테스트 코드는 왜 작성할까? 사실 백엔드 개발을 학습하면서 "테스트 코드가 중요하다. 실무에서 매우 중요하다." 이런 말을 정말 수도 없이 많이 들었었다. 하지만 이전까지 나의 프로젝트 경험을 돌아보았을 때 나 자신에게도 "중요하다. 중요하다." 되뇌기만 하였을 뿐 실질적으로 프로젝트 내에서 진행한 적은 없었다. 이런 상황에서 네이버 부스트캠프에서 곰터뷰 프로젝트를 진행하면서, 꼭 테스트 코드를 프로젝트에 적용해보고 싶다는 생각을 하였었다. 다행히도 함께 백엔드 파트를 진행하신 팀원분께서 테스트 코드를 사용하신 경험이 있으셨기에, 큰 부담 없이 테스트 작성을 학습해 가며 진행할 수 있었다. 학습을 통해 알게 된 테스트 코드를 작성하는 이유를 정리해보고, 또한 프로젝트를 통해 직접 테스트 코드 작성을 경험..
SSAFY 11기 전공자 합격 후기 (면접 스터디 X)
SAFFY 11기에 지원하여 합격하였기에 어떤 방식으로 선발 과정이 진행되고 또 어떻게 준비하였는지 정리를 하면 다른 지원자들에게 큰 도움이 될 것이라고 생각하여서 전체적인 과정을 간단하게 정리해보고자 한다.지원서지원서는 매우 간단한 양식이었다. 인적사항, 학력, 교육희망지역, 경력 등 아주 간단한 개인정보를 입력하면 된다.인적사항이 당락에 영향이 크게 있진 않겠지만, 참고로 필자의 경우에는 인서울/3.8/컴퓨터공학과 전공생이었고, 경력과 자격증은 없었고, 1지망 - 서울/2지망 - 대전으로 지원하였다.에세이에세이의 경우에는 지원서 마감일 다음날부터 그 주의 주말 정도까지 입력해야 했다. 걱정과는 다르게 에세이의 경우 하나의 질문만 작성하면 되었기에 시간적인 여유는 충분했다.SW 관련한 경험과 SAFFY..

(CS) 무중단 배포
프로젝트나 서비스 개발에 백엔드 개발자로 참여하였을 때, 로컬이 아닌 실제 환경에서 개발한 기능들을 테스트하고 또 사용하기 위해서 반드시 진행해야 하는 작업이 있다. 그것은 바로 배포이다. 1년이 넘는 시간 동안 백엔드 개발을 많이 진행하였기에 여러 번 배포를 진행하였지만, 무중단 배포에 대해서는 들어만 보았을 뿐 정확하게 어떤 방식으로 진행되는지에 대한 학습조차 되어 있지 않았다. 현재 진행 중인 프로젝트에서 무중단 배포를 진행해 볼 기회를 얻어서 이에 대해 학습 후 정리해보고자 한다. 배포란? 무중단 배포에 대해 정리하기에 앞서 배포가 무엇인지 먼저 간단하게 알아보고자 한다. 배포라는 단어 자체는 원래 신문이나 책자 등을 널리 나누어주는 행동을 나타내는 말이다. 소프트웨어 관점에서 말하는 배포도 역시..

(CS) 계수 정렬 & 기수 정렬
계수 정렬(Counting Sort)과 기수 정렬(Radix Sort)은 비교 정렬이 아닌 정렬 알고리즘으로, 특정한 상황에서 매우 효과적인 알고리즘이다. 각 정렬 알고리즘에 대해 자세하게 알아보자. 계수 정렬 계수 정렬은 범위에 해당하는 각 숫자의 빈도수를 계산하고, 빈도수의 누적값을 사용하여 데이터의 위치를 결정하여 정렬하는 알고리즘이다. 정렬할 데이터의 범위를 알고 있을 때 매우 효과적인 정렬 알고리즘이다. 비교 정렬이 아니기에 특정 상황에서 매우 빠르지만, 정렬할 데이터의 범위만큼의 추가적인 메모리가 필요하다. 정렬 과정 데이터들의 최솟값과 최댓값을 확인하여 전체 범위를 파악한다. 범위에 해당하는 각 숫자의 빈도수를 세어 배열에 저장한다. 각 숫자의 빈도수를 누적하여 해당 숫자의 정렬된 위치를 계..